- RN Forward
- Posts
- 🗞️ Badge-in for AI Safety
🗞️ Badge-in for AI Safety
This edition breaks down the clinical AI benchmarks, what nurses need to watch for, and how to pressure-test models for bias, safety, and real-world impact.
Niki Pham
July 18, 2025
Team Huddle
We’re going to try something a little different this newsletter. Instead of top headlines, I’m going to talk AI benchmarks.
A couple months ago, HealthBench by OpenAI was published. This marked the industry’s first large scale, open source, conversation focused benchmark that was validated by dozens of physician in multiple specialties and care contexts. Since then, many other benchmarks, rubrics, guidelines, [insert more framework synonyms here] have been released. Idk about you, but my brain is scrambled eggs from reading them all. 😵💫 These benchmarks are important for many reasons. For Nurse Innovators building in Healthcare + AI, this is how stakeholders will grade you. For active clinicians, this is how your committees should be vetting these vendors because there are no policies holding these companies to a safety standard.
I’ll be breaking down the takeaways from my personal top 3 (in no particular order) to save you the headache.

Benchmarks Nurses Need to Know
Rubric for Healthcare AI Governance by a (relatively) independent MD, Sarah Gebauer.
Breakdown: Drawing from existing standards like CHAI, NIST, and ISO, Sarah turned her rubric into something easily palatable and usable. It contains 7 domains, each scored 0–3. Numbers are then categorized from lowest to highest. High (numbers) being good. 😏
Its the most simple of the 3 reviewed today therefore it does have multiple limitations. This one rubric is more for an audience who at the pre-implementation stage and is screening if a tech product is a flop or a full send. It also has not been validated, assumes user has complete data access to answer all questions, and takes a long time for users to complete.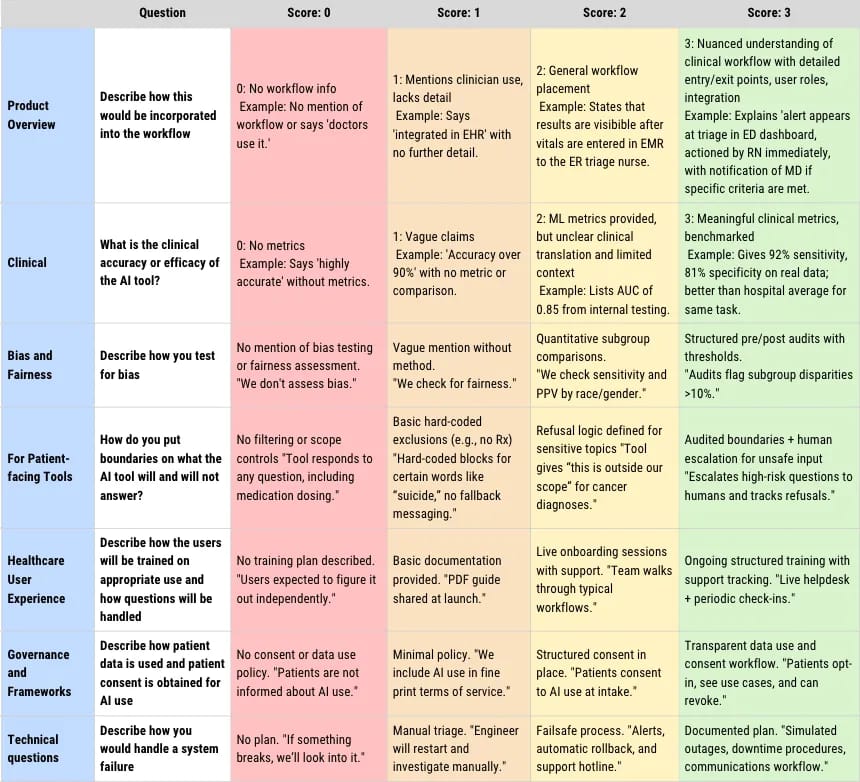
Validara AI Governance Scoring Rubric by Sarah Gebauer, MD.
AI governance in oncology through Memorial Sloan Kettering’s (MSK) binoculars.
Breakdown: MSK created their Responsible-AI Governance Committee (AIGC) tasked with the job of logging every model it uses and rate each one’s risk. They reviewed an impressive 26 AI models, 2 ambient pilots, and 33 calculators in 1 year. Furthermore, they developed a process to lower risk models for 2 week time frame approvals a la Disney fast pass style.
They did well to weave their processes into existing digital governance structures using iLEAP (Integrated Lifecycle Evaluation and Approval Process) and TrAAIT (Trust and Acceptance Assessment Instrument for Technologies, and evidence based surveying tool). All while while taking into account oncology-specific risk factors. Its the most mature governance org-chart and tooling article of the 3 examined today.
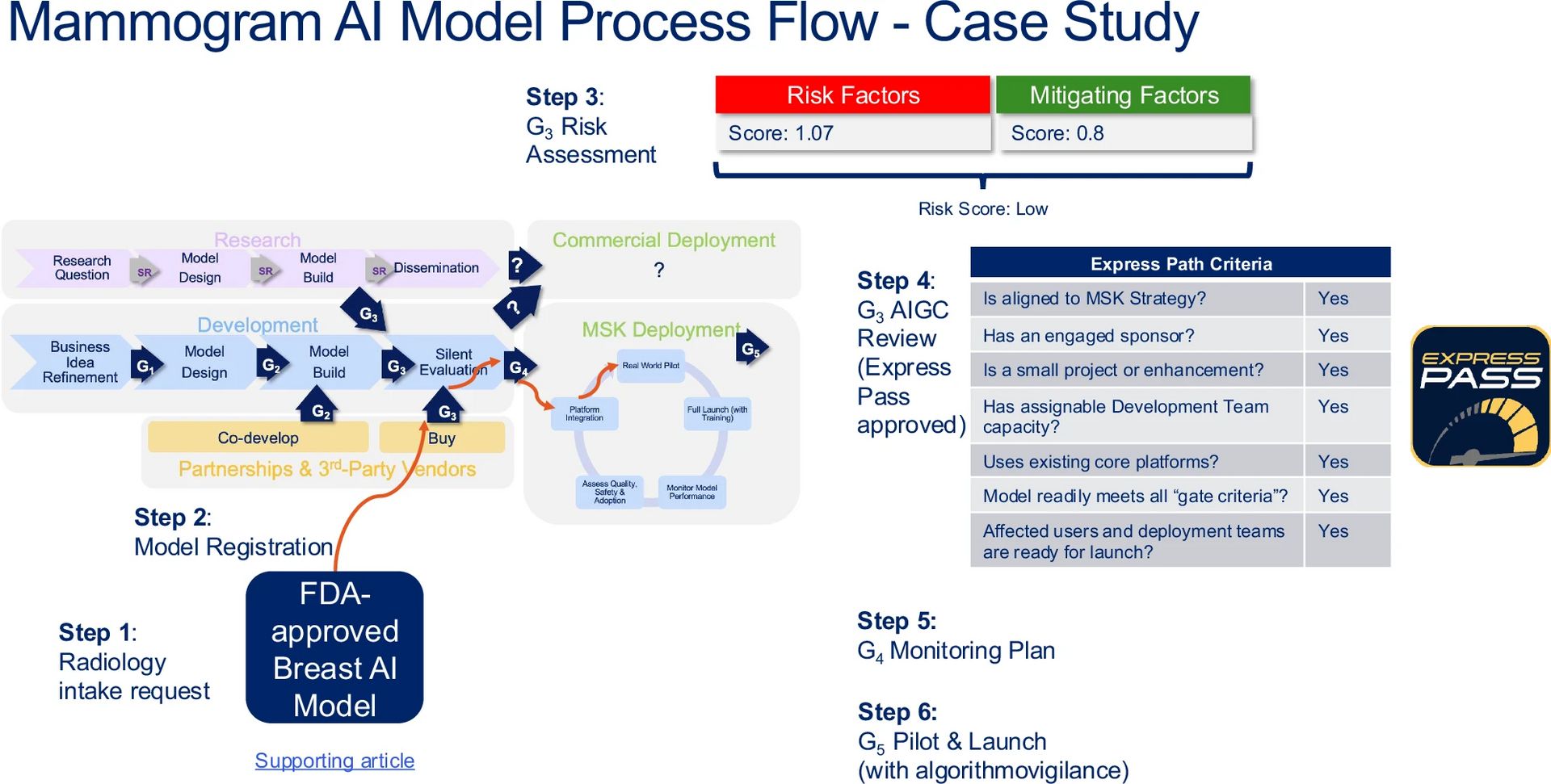
Real-world example of an acquired FDA-approved radiology AI model from a 3rd-party vendor, and the steps on the path it followed through the lifecycle management stage gates. iLEAP Legal, Ethics, Adoption, Performance; FDA Food and Drug Administration, AIGC AI Governance Committee. Source: Memorial Sloan Kettering.
Comprehensiveness comes at a cost though. Its resource-heavy — requiring lots of staff time, is limited to oncology in scope, sparse in equity evidence, and success metrics (clinical impact, equity) have yet to be fleshed out.
Duke Health’s evaluation framework for ambient digital scribing tools in clinical applications
Breakdown: Duke built a multilayered evaluation pipeline to review ambient scribes, a model they call “SCRIBE” (Simulation, computational, reviewing, intelligent/LLM). Not sure there the “B” and “E” are coming from tbh. But I digress.
They evaluated 40 prenatal-visit recordings. Different metrics are used depending on the stage of the recording. Word error rate (WER), diarization error rate (DER) for transcription stage, ROUGE and BERTScore for summarization, etc. They also differentiated who did the scoring: Human, Auto (ROUGE metric), trained-auto (machine learning-based evaluators rained for specific tasks), and LLM scorers (AI models grading other AI’s work).
Results show that GPT-4 generated notes did better than LLaMA on the ROUGE and BERT metric while bias testing showed mixed results. There was no major performance gap between different racial groups but toxicity (harmful or offensive language) varied depending on race making some responses more problematic for certain racial groups.
Duke does well to combine multiple stress tests into one rubric however there was note of possible inflation bias when the GPT evaluator graded GPT output. Testing has yet to be done on commercially available tools. They only tested on internal prototypes.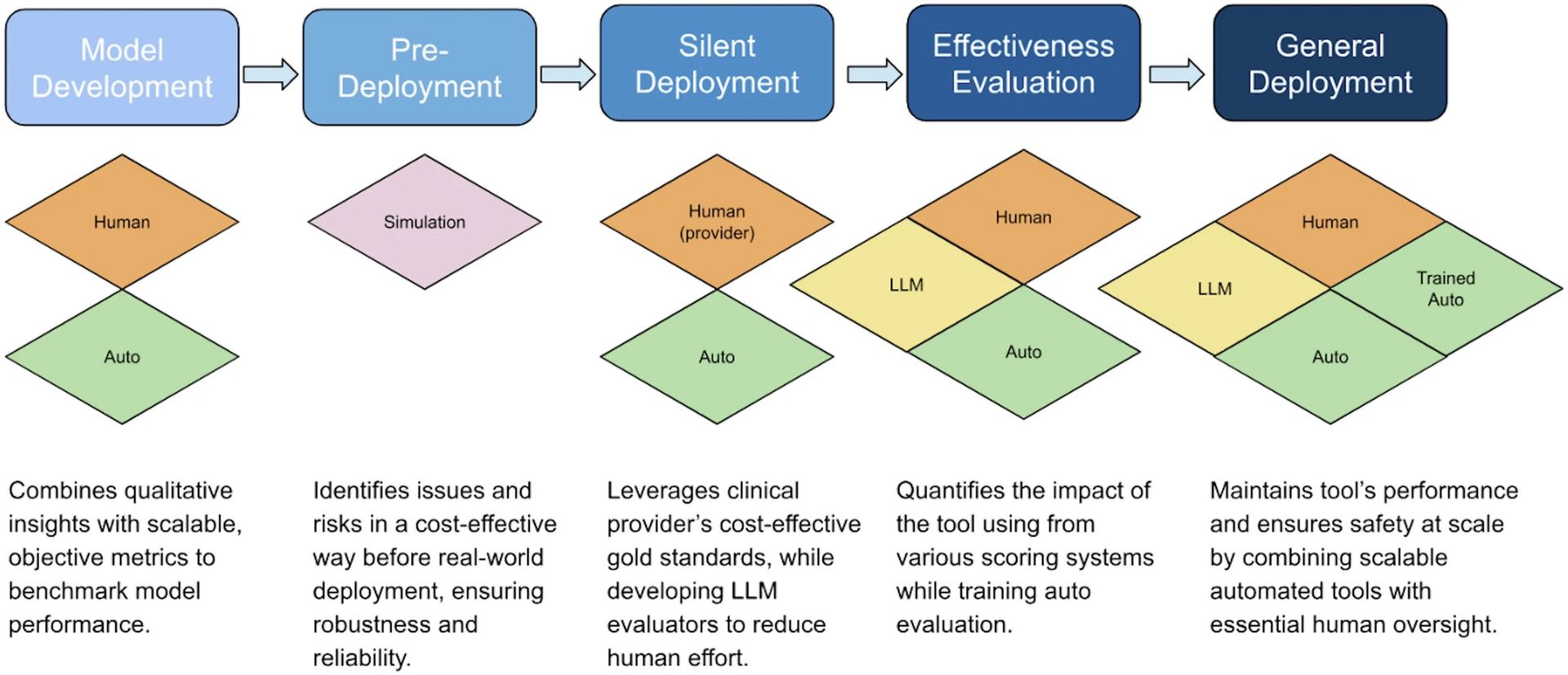
This figure illustrates the application of the proposed evaluation framework across the model development lifecycle, building upon the existing CHAI governance model to enhance transparency, accountability, and ethical ADS deployment.
Overall, it was strongest on technical rigor and can be easily taken to apply to other AI tools but made no mention overall oversight or how to implement it into existing governance workflows.
Actionable Takeaways:
→ Adopt layered governance. One size fits all (unfortunately) does not work. A master list of all the AI tools and give each a risk rating (re: Oncology AIGC model). For data heavy tools, run quantitative testing like the SCRIBE framework. For lower-risk tools, shorter checklists like Sarah’s rubric are sufficient and fast.
→ Mandate transparent, auditable metrics before go—live. Require vendors to publish objective scores IN ADDITION to regular human audits. Auto-scores don’t cut it alone; they can overrate the model (See Duke article).
→ Check if its unbiased and fair. Use simulated tests checking if accuracy drops for certain racial groups, genders, age, etc. Also make sure the model avoids slurs, stereotyping or harmful content. Otherwise, Risk Management will be quivering in their boots. 🥺 🙏🏼
→ Its okay to fast-track low-risk, high-value models (without skipping monitoring tho pls). Examples of these are tools that are already FDA-cleared or where a clinician in still in control. Still require frequent check-ins to make sure it hasn’t gotten worse over time.

Funding Announcements
💸 = Hiring potential. Follow these companies closely to see Nurse-qualified positions posted. Remember: Just because some positions don’t say “Nurse”, doesn’t mean you aren’t qualified!
Vytalize Health, a VBC enablement platform for physicians, raised $60M.
Abridge, arguably one of the top 3 ambient scribe companies raised a Series E of $300M, and is now valued at $5.3B. They’re clinician led!
NPHub, a platform for matching Nurse Practitioners Students to preceptors and NP Graduates to jobs, raised $20M.
SuperDial, an AI startup helping automate admin heavy Revenue Cycle Management (RCM) calls, raised $15M.
Handspring Health, a virtual mental health provider for families and children, raised a $12M Series A.
Circulate Health, a company that came out of stealth peddling plasma exchanges with IVIG infusions as an anti-aging/longevity play (🙄), raised $12M. For what its worth, its “evidenced-based”.
Note: If you’re seriously considering on working for this company, DM me because i’ve worked for wellness and specialty infusion companies and will share the going pay rates so you at least don’t get jipped. lol.
Other Notable Reads, Webinars, and Podcasts
READ
📚 Common ROI mistakes in healthcare by Out Of Pocket Health
📚 N.U.R.S.E.S. embracing artificial intelligence: A guide to artificial intelligence literacy for the nursing profession by Stephanie Hoelscher and Ashley Pugh
📚 The regulation of clinical artificial intelligence published by the NEJM
LISTEN
🎧 Innovation and AI-driven healthcare with Dr. Jay Parkinson at Offcall Podcast
🎧 AI prompt engineering in 2025: What works and what doesn’t with Sander Schulhoff from Lenny’s Podcasts
🎧 Launching a new division of clinical informatics with Julia Adler-Milstein, PhD
WATCH
📺 Startup strategies for nurses: Funding, bootstrapping, and getting started webinar with LinkedIn in partnership with Nurses Feed Their Young
📺 Scaling AI Scribes: Lessons from front line of AI scribe adoption with Elion Health featuring Nurse baddie Abigail Baldwin-Medsker from MSK
📺 M7 Health’s Why nurses make the best entrepreneurs: Ilana’s story webinar
✍️ On The Blog

Forward Nursing: Learning Opportunities 🏃🏻♀️
Round-up of learning and career development opportunities i’ve come across that can help nurse innovators like YOU! (Not sponsored or affiliated with RN Forward.)
Healthcare x AI Agents Hack & Learn
TBH: Hosted by Autoblocks and one of my favorite people to follow on LinkedIn, Healthcare AI Guy. You can participate as a builder or attend the event as a viewer and see the products build on Demo Day. Don’t have a team? Don’t worry, you can apply individually and they’ll help match you to a team on-site. Other perks include building with the latest and greatest tools, listen to lightening talks from leading voices in AI x Healthcare, on-site mentorship, and free food of course!
When: July 31 - August 1, 2025 (Thursday and Friday)
Where: New York City, NY
Cost: Free
Apply to be a builder by July 21, 2025.
Register to attend Demo Day
TBH: Not in NYC? No worries, this hackathon is remote. Its recommended for teams of 2-3 people. The goal is to build AI Agents or AI Agent related tools. Of note, this one is not AI related and is more of a scrappy “underground like” event but they do have prizes!
When: August 2, 2025 (Saturday)
Cost: Free
Register to participate
Applications opened for Pear VC’s Female Founder Circle AI 9th Cohort
TBH: I personally know a female founder within this cohort and she is someone I deeply admire and confide in. The community they build is trusted, sincere, and filled with ambitious female industry leaders. It is a 10 week curriculum leading to a celebration event with alums. Perks include 3 month access to the Pear SF Studio, lessons from industry experts and AI CEOs, to Cloud and APO credits from top AI models.
Don’t be put off by the requirement saying “engineers”. I have it confirmed personally that clinical expertise counts as technical expertise. I mean haven’t you heard, Physicians — né clinicians — CEOs are the next specialty according to McKinsey. Female Nurse Founders looking for a strong network, this is the community for you!
Due Date: July 31, 2025
Where: San Francisco, CA but anyone in the world can apply.
Reply